
Abdelghny Orogat
Concordia University
PhD: Computer Science, Carleton University
Research
My research addresses fundamental challenges in how AI systems can reason effectively over structured knowledge. I develop methods for decomposing complex reasoning tasks across specialized agents, designing comprehensive evaluation benchmarks, and building scalable knowledge graph systems for real-world applications.
Multi-Agent Systems
My research investigates the design, evaluation, and automation of large language model-based multi-agent systems (MAS). I study how architectural choices such as orchestration structure, memory organization, planning interfaces, agent specialization, and communication topology fundamentally affect system performance, scalability, and coordination. A central focus of this work is developing controlled benchmarking methodologies that isolate architectural effects from model capability. Through large-scale empirical evaluation across popular multi-agent frameworks, my research demonstrates that framework-level design choices alone can induce order-of-magnitude differences in latency, accuracy, and coordination success. Building on these insights, I develop systems for automating multi-agent architecture design from natural language specifications, enabling systematic exploration of MAS design spaces and rapid prototyping of complex agent workflows. I apply these architectural principles to real-world multi-agent reasoning systems, including large-scale knowledge graph question answering platforms such as Chatty-KG, which decompose complex reasoning into specialized agents for entity retrieval, query planning, validation, and execution.
MAFBench: Multi-Agent Frameworks Benchmark
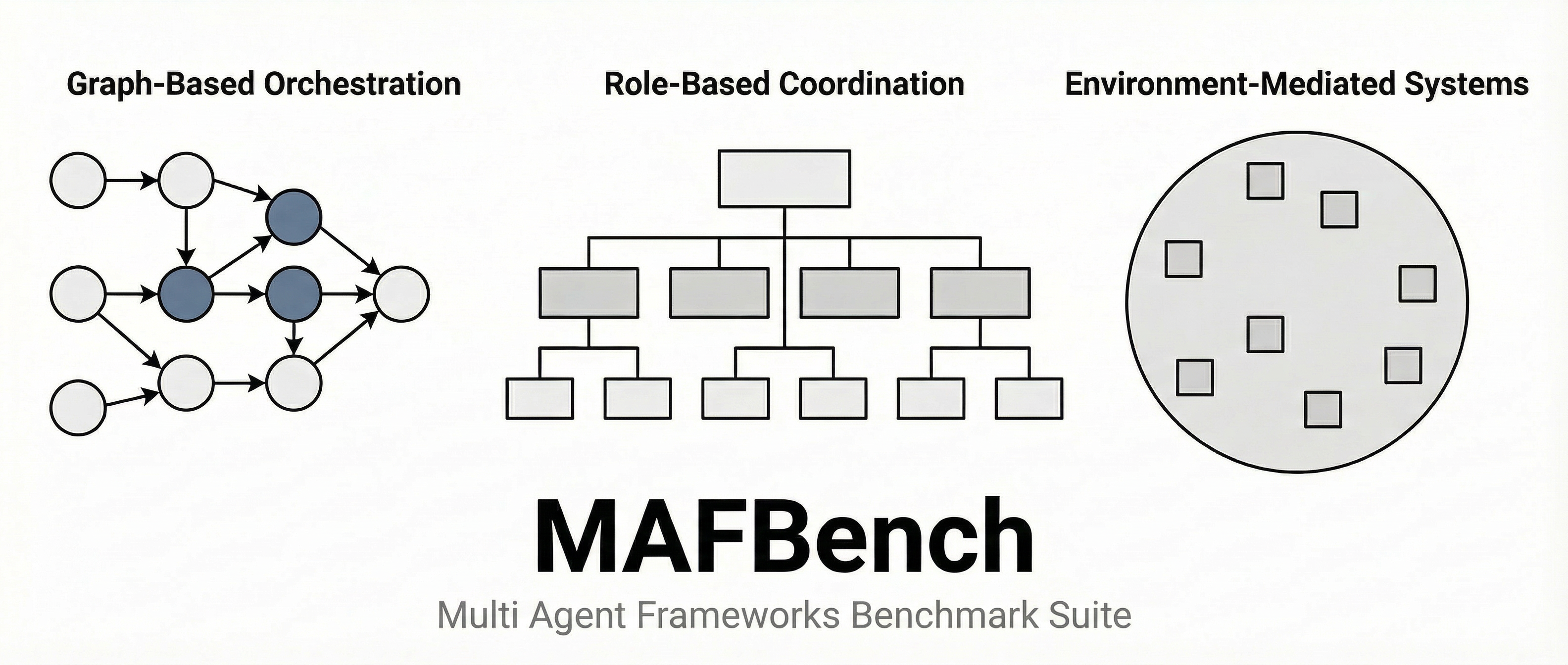
MAFBench is a unified and reproducible benchmark suite for evaluating single-agent and multi-agent LLM frameworks under standardized execution conditions. It systematically measures orchestration overhead, memory behavior, planning strategies, specialization effects, tool use, and coordination protocols, enabling fair architectural comparison across frameworks.
Project Website CodeMAS-Automation: Natural Language MAS Design

MAS-Automation is an interactive system that translates natural language requirements into complete multi-agent architectures. The system supports automated requirement elicitation, agent role definition, communication topology selection, and workflow generation, facilitating rapid MAS prototyping and design optimization.
CodeQuestion Answering over Knowledge Graphs
A comprehensive research program addressing the full pipeline of knowledge graph question answering: from benchmark design and evaluation methodologies to large-scale dataset creation and multi-agent system architectures. This work spans systematic evaluation frameworks, automated benchmark generation, million-scale annotated datasets, and production-ready QA systems.
Chatty-KG: Multi-Agent QA System
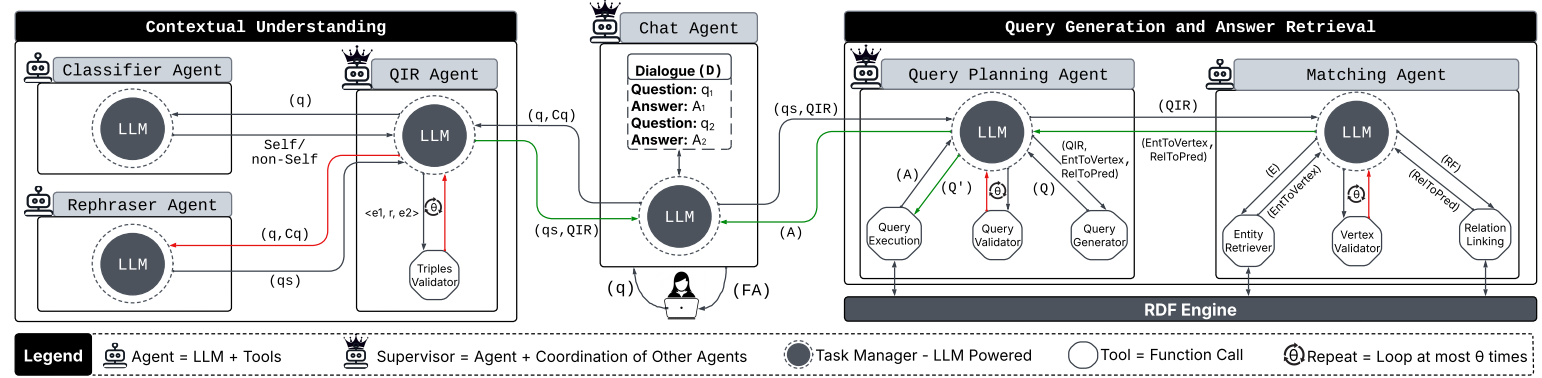
A LangGraph-based multi-agent KGQA system that decomposes reasoning into specialized agents for entity retrieval, query planning, validation, and execution over large knowledge graphs.
arXiv CodeQueryBridge: Large-Scale Dataset

1+ million natural language questions paired with executable SPARQL queries. The largest annotated KGQA dataset, enabling research on complex query structures and semantic diversity.
Paper Code Hugging Face Project Website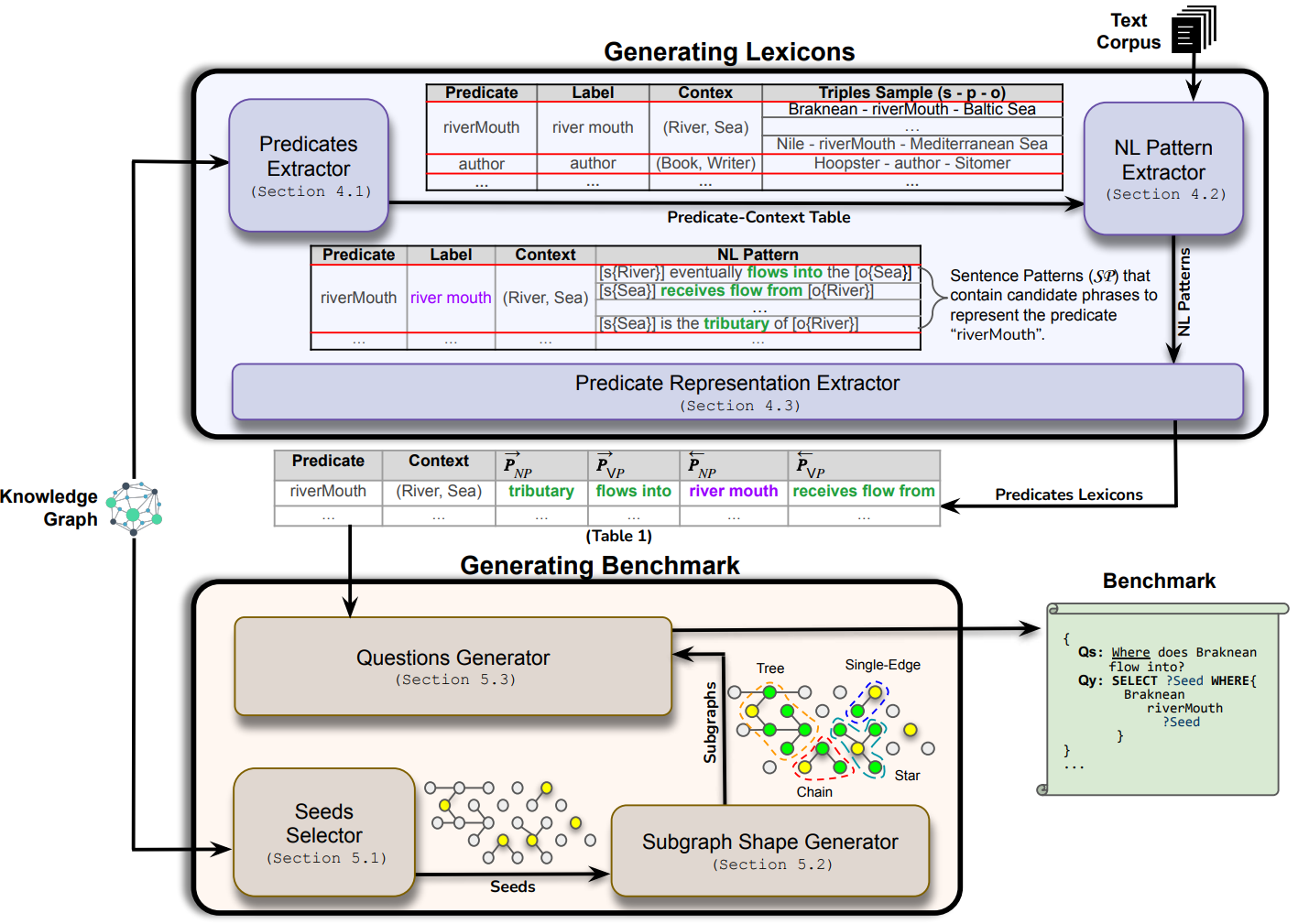
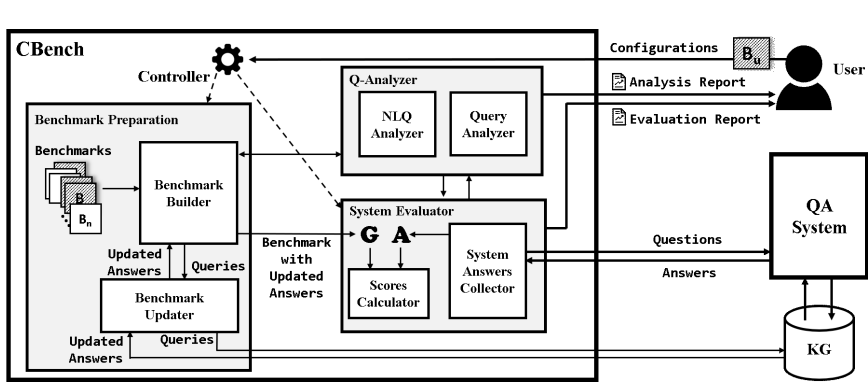
Enterprise Knowledge Graph Systems
Applied research in production knowledge graph platforms for enterprise analytics, semantic search, and operational data management.
Ericsogate: CloudRAN Analytics Platform
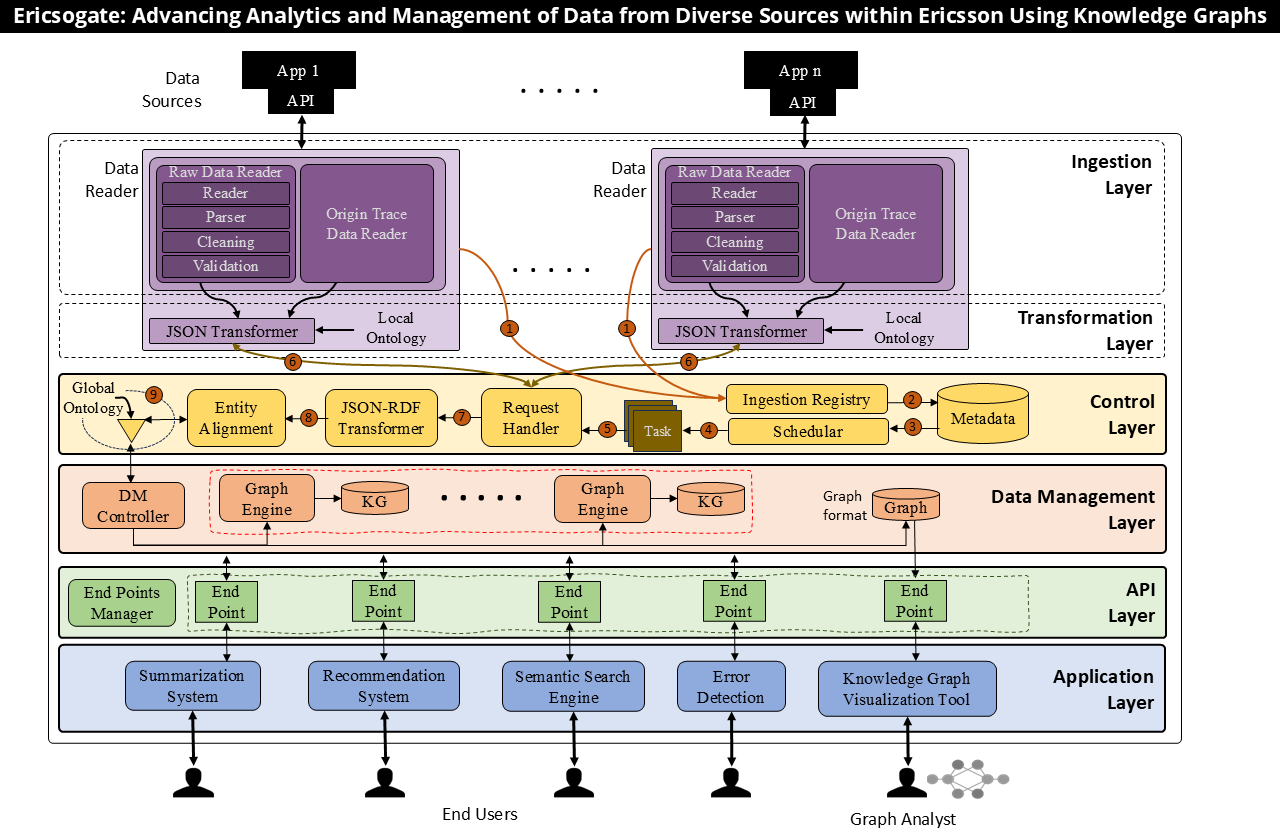
Production-grade knowledge graph platform for CloudRAN analytics at Ericsson. Provides semantic search, automated summarization, and retrieval-augmented exploration over heterogeneous operational data.
Paper Project Page