Maestro: The Generation Framework
QueryBridge is systematically generated via Maestro, the first framework to automatically produce comprehensive, utterance-aware benchmarks for any targeted Knowledge Graph.
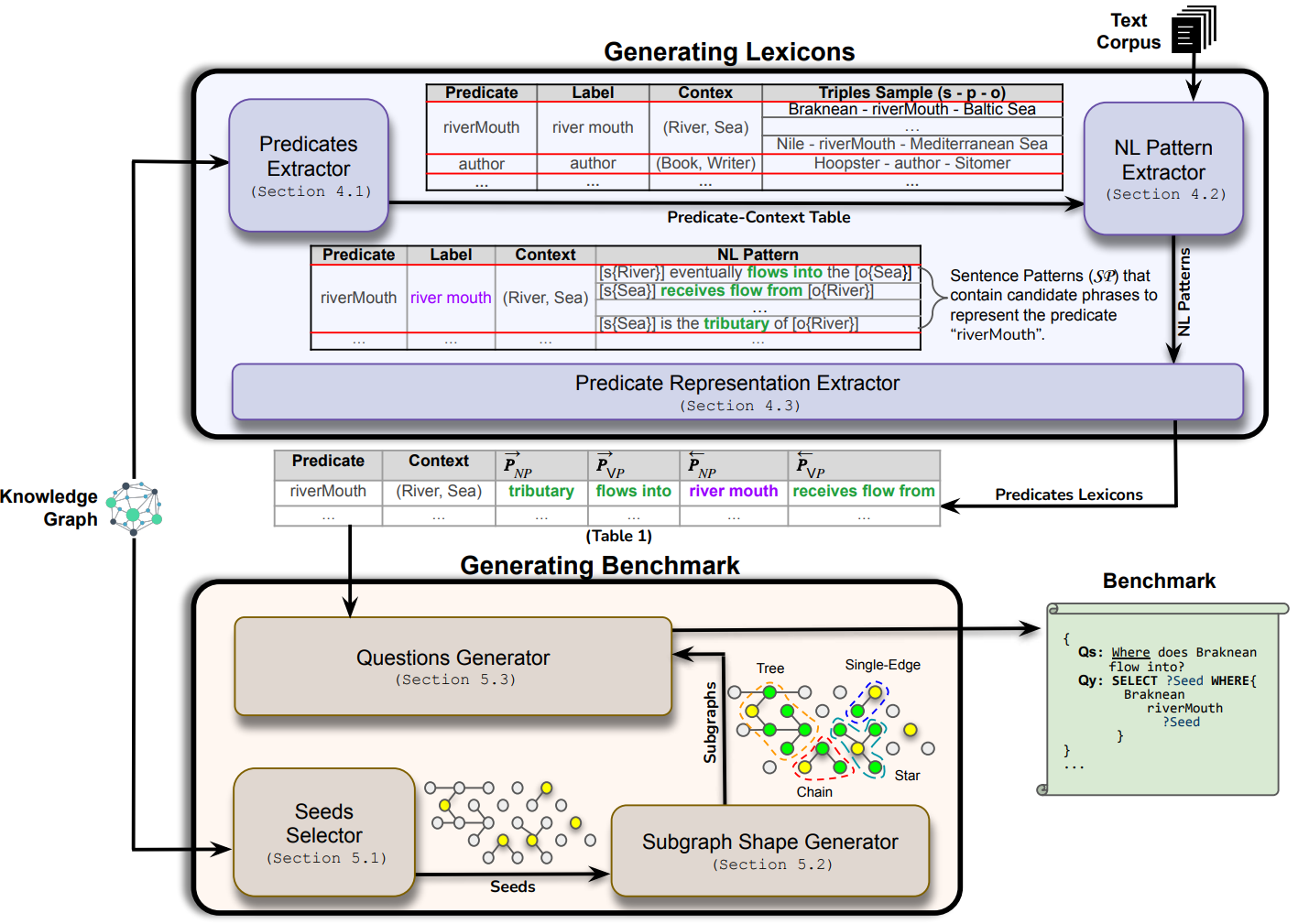 Figure 1: Maestro architecture for automated benchmark generation. The system (1) selects representative seed entities, (2) instantiates diverse query shapes over the KG, and (3) lexicalizes graph patterns into natural language.
Figure 1: Maestro architecture for automated benchmark generation. The system (1) selects representative seed entities, (2) instantiates diverse query shapes over the KG, and (3) lexicalizes graph patterns into natural language.
Resilience to KG Evolution
Static benchmarks become stale as KG ontologies evolve. Maestro addresses this by traversing the graph starting from selected seeds to find all valid subgraph shapes, ensuring benchmarks remain accurate.
Utterance-Aware Lexicalization
By mapping external text corpora to KG predicates, Maestro captures semantically-equivalent utterances. This results in high-quality natural language questions that are on par with manually-generated ones.
Bias-Free Sampling
Instead of random selection, Maestro uses Class Importance ($I_c$) and Entity Popularity ($P_e$) heuristics to ensure representative sampling of both common and tail entities.