Six-Layer Architecture
Each layer addresses specific requirements: data provenance, quality assurance, entity alignment, horizontal scalability, access control, and data freshness.
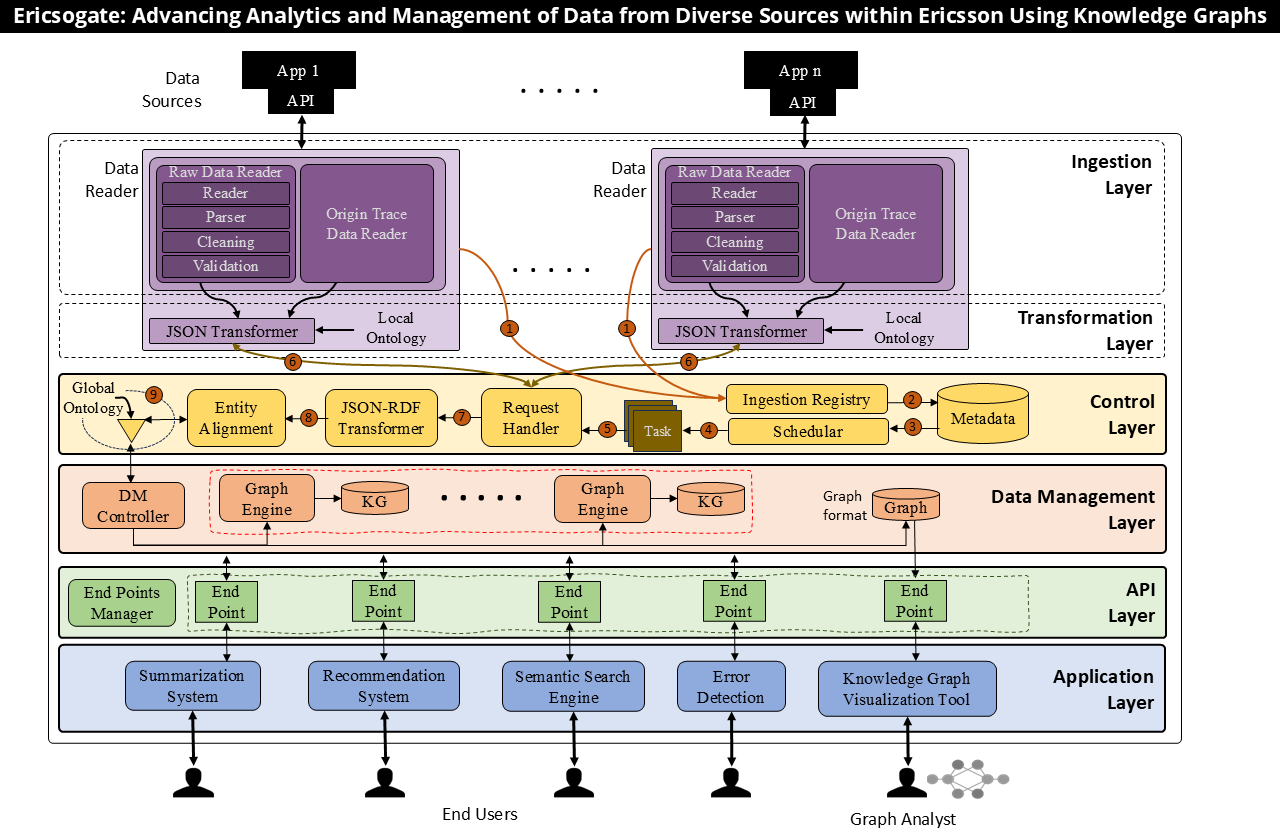
Figure 1. The six-layer architecture showing data flow from ingestion through transformation, control, storage, API exposure, and application consumption.
Ingestion Layer
Interfaces with heterogeneous data sources via APIs, extracting entities and properties from structured, semi-structured, and unstructured content.
- Raw Data Readers: Source-specific adapters for databases, APIs, log files
- Parsers: Regular expressions to ML models for entity extraction
- Data Cleaning: Duplicate removal, spelling correction, format normalization
- Origin Trace: Metadata capture for provenance tracking
Transformation Layer
Converts heterogeneous formats into standardized JSON triples (subject-predicate-object), enriched with local ontologies defining source-specific class hierarchies.
- JSON Transformers: Source-specific conversion to uniform triple format
- Local Ontologies: Class hierarchy for each data source
- Developer Interface: Standard JSON libraries, no RDF expertise required
Control Layer
Orchestrates the data pipeline: schedules ingestion tasks, aligns entities across sources, and integrates local ontologies into a global schema.
- Ingestion Registry: Tracks data sources and refresh rates
- Scheduler: Automated refresh from milliseconds to days
- Entity Alignment: Local and global matching using lexical and contextual similarity
- JSON-RDF Transformer: Converts to RDF for storage
Data Management Layer
Stores the Knowledge Graph using Apache Jena triple stores, distributed across multiple engines for horizontal scalability with federated SPARQL queries.
- Triple Store: Open-source Apache Jena for RDF storage
- DM Controller: Data distribution across graph engines
- Federated Queries: Transparent querying across distributed stores
- Single-Graph Facade: Applications see unified graph
API Layer
Exposes REST APIs returning JSON, abstracting SPARQL complexity. Provides granular access control through credential-protected endpoints.
- Endpoint Manager: Dynamic API endpoint generation
- Request Handler: Translates REST to SPARQL
- Access Control: Unique credentials per endpoint
- JSON Response: Standard format for application layer
Application Layer
User-facing applications leveraging the Knowledge Graph: semantic search dashboards, summarization tools, recommendation systems, and error detection.
- Semantic Search: Meaning-based queries across linked data
- KG Summarization: 100K nodes to 100 insights
- Recommendations: Related tests and configurations
- Pattern Detection: Cross-failure analysis